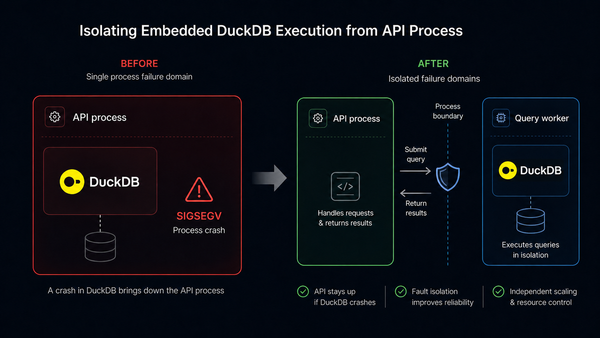
DuckDB Solved the Query Engine. The Workflow Around It Is Still Messy.
DuckDB made cross-source SQL practical. But once queries need credentials, schema inspection, exports, and repeat runs, the workflow around the query becomes the hard part.
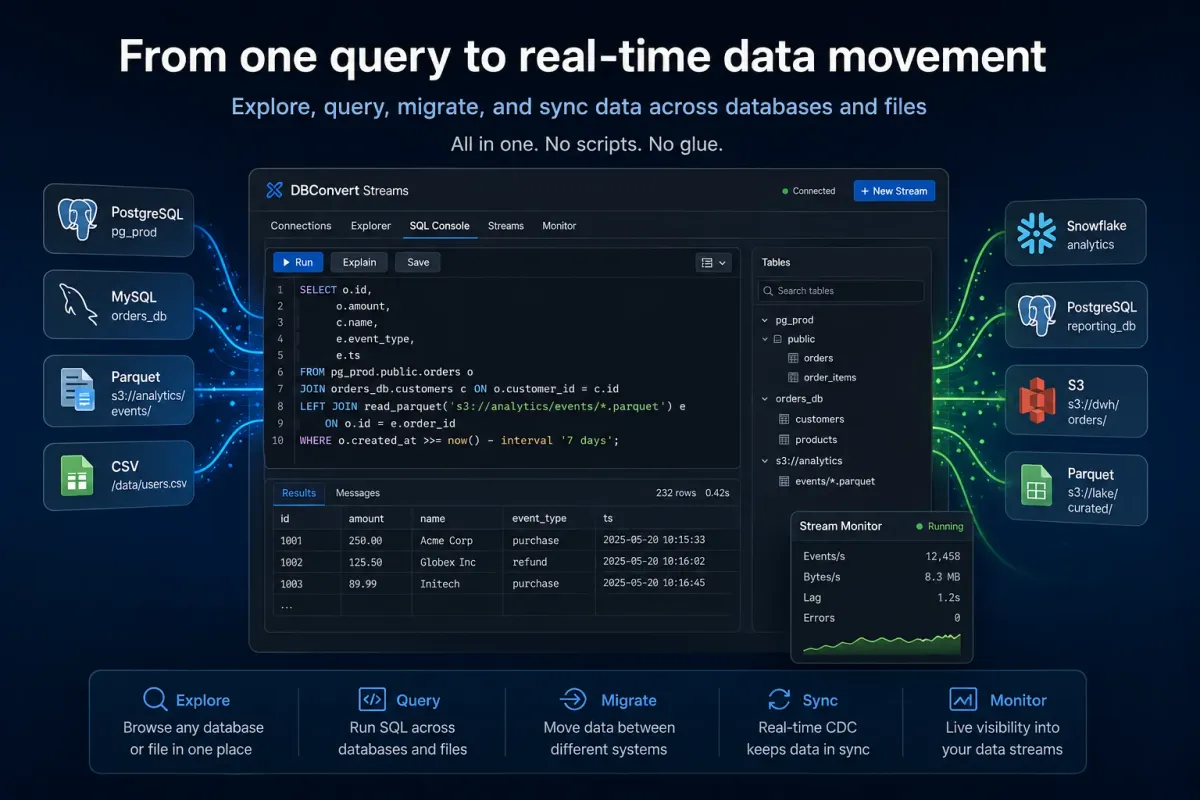
DuckDB changed what counts as a "simple query."
A few years ago, if data lived in different places, the workflow usually became ugly fast. One table was in PostgreSQL. Another dataset was in Parquet. Some files were sitting in S3. A quick check turned into exports, staging tables, notebooks, temporary scripts, and a folder called final_final_2 that everyone pretended not to see.
DuckDB made a lot of that feel unnecessary.
It can read Parquet directly, work with object storage through httpfs, and attach PostgreSQL through the PostgreSQL extension. A lot of work that used to require exports, staging tables, or a small ETL job can now start as plain SQL.
That is the good news.
The messy part is what happens after the query works.
The question is no longer only:
Can this engine query the data?
Often, the more annoying question is:
Can this workflow be trusted again next week without rebuilding everything around it?
DuckDB solved a large part of the query engine problem.
The workflow around it is still scattered.
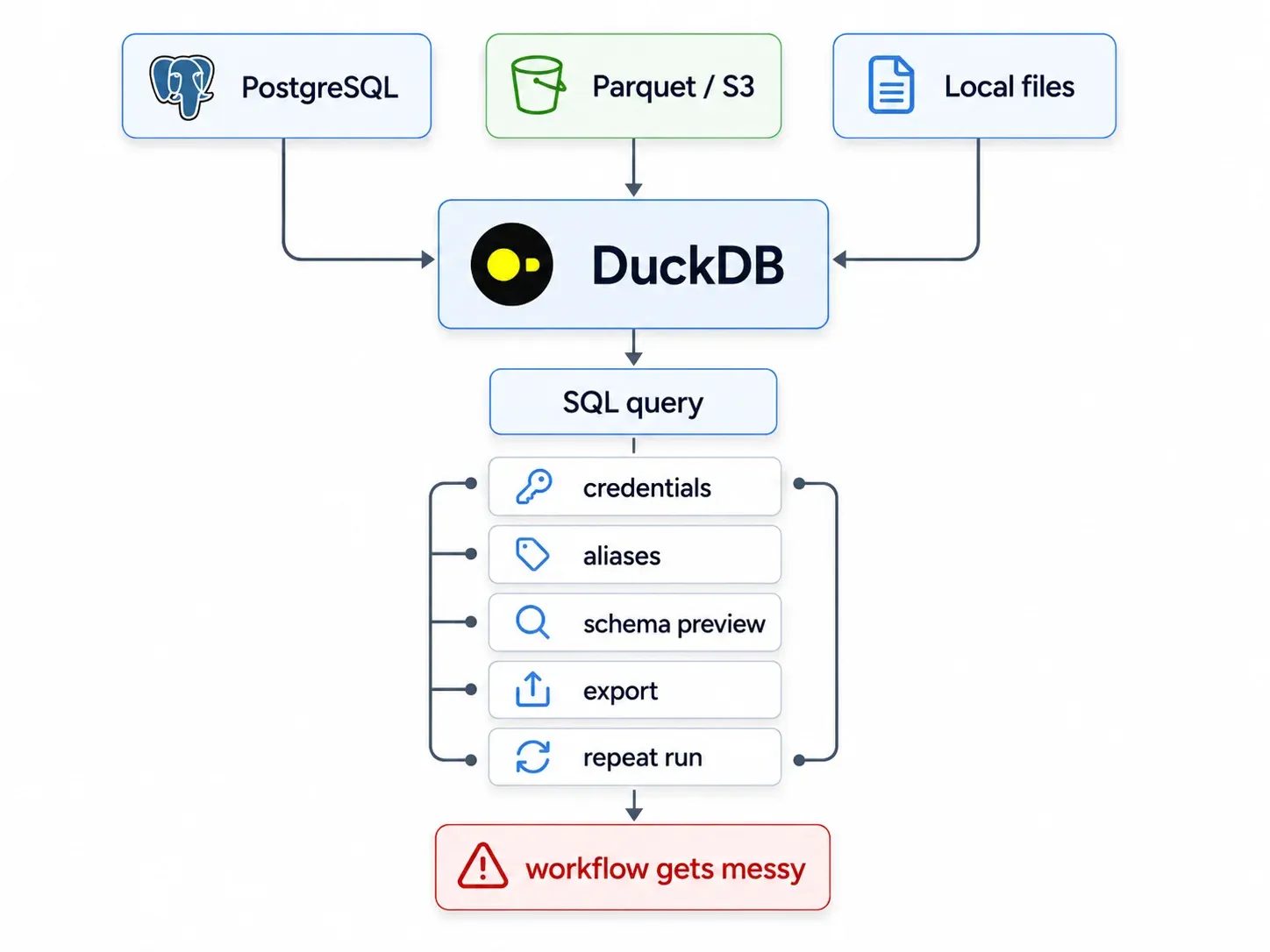
DuckDB made cross-source SQL practical
The appeal is simple: use SQL where the data already lives.
Databases, files, and object storage no longer have to mean three separate query workflows. Instead of moving data first and asking questions later, DuckDB lets you ask the question closer to the source.
For example, the interesting part is not that you can write a clever SQL query like this:
SELECT
u.id,
u.email,
count(e.event_id) AS event_count
FROM pg_prod.public.users u
JOIN read_parquet('s3://analytics/events/*.parquet') e
ON e.user_id = u.id
GROUP BY u.id, u.email
ORDER BY event_count DESC;
The interesting part is that this kind of query does not need to start with "first, export everything."
No warehouse staging step. No manual CSV detour. No throwaway import table. No small pipeline just to compare two datasets.
At least, not at first.
When the wrapper starts owning the job
The first version is usually innocent: a small Python script wraps a DuckDB query, loads credentials, attaches a database, reads a few files, and writes the result somewhere.
That is a perfectly reasonable way to explore. Python is fast to change, DuckDB fits naturally into local scripts, and the first result arrives quickly.
The problem starts when the wrapper keeps collecting responsibilities. It now owns database credentials, S3 paths, aliases, export logic, a config file, logging, retries, and a recurring schedule. Nobody planned to build a pipeline, but the script quietly became one.
quick_test.py
├─ credentials
├─ S3 paths
├─ aliases
├─ export logic
├─ logging
├─ retries
└─ scheduleThat is usually the point where the query is no longer the problem. The SQL still works. The fragile part is everything needed to run it again with confidence.
Schema inspection is part of that confidence. Before trusting a cross-source query, you still need to know which tables exist, what columns are available, what the Parquet file contains, and whether user_id is an integer, UUID, string, or some historical accident with leading zeroes.
A raw script can do all of this, eventually. But now the script is not just running SQL. It is managing context.
What this looks like in DBConvert Streams
This is the part DBConvert Streams takes out of the script.
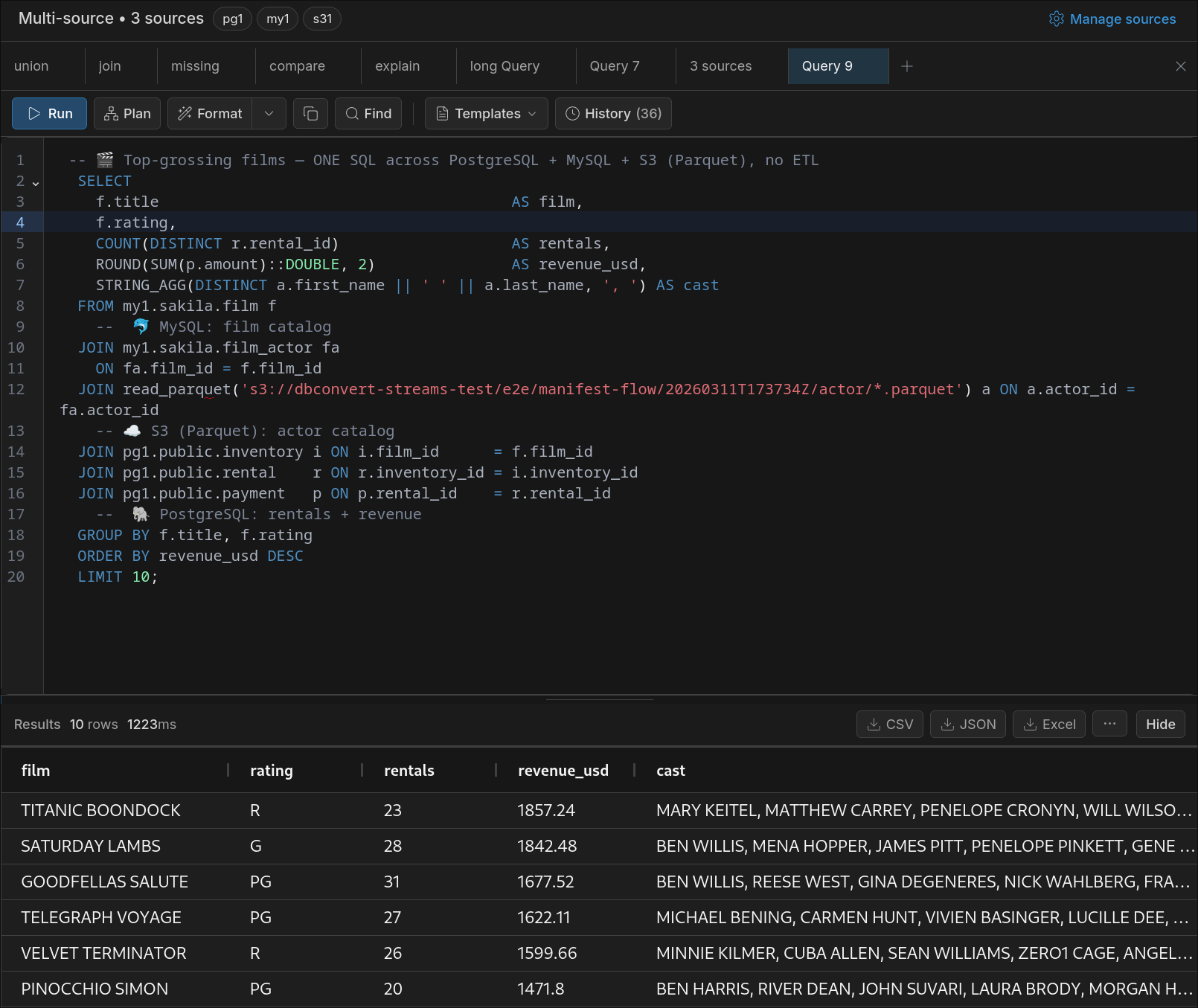
The query in the screenshot returns a single result table with top-grossing films, rating, rental count, revenue, and cast list.
No export from MySQL.
No staging table for Parquet.
No temporary PostgreSQL import.
No separate script just to glue the sources together.
In a script-first workflow, the SQL is only one piece. The rest is hidden in code: connection strings, credentials, S3 paths, aliases, output locations, cleanup logic, and whatever gets added after the query starts being reused.
In DBConvert Streams, those parts live in the workspace instead. Connections are saved. S3 sources are visible. Schemas and rows can be inspected before writing the query. The SQL still runs through DuckDB, but the surrounding workflow is no longer scattered across a script, a database IDE, and a separate export or migration tool.
The result can also become a source for a Stream. That matters when the query is not just analysis, but preparation: join data from several places, filter it, validate the shape, and then load the result into another database or file target.
That is the positioning:
DuckDB is the engine.
DBConvert Streams is the workspace around the engine.
The goal is not to replace DuckDB. The goal is to stop turning every useful DuckDB query into a small custom tool that somebody has to maintain.
A simple rule of thumb
Plain DuckDB is enough when the task is local, temporary, and owned by one person.
A workflow layer starts to make sense when the same sources come back again, credentials matter, schemas need to be inspected, or the query result becomes something people depend on.
That is the line to watch. Not the moment the query becomes complex, but the moment the workflow becomes worth preserving.
That is where Cross-Database SQL fits: keep DuckDB as the engine, but stop leaving the rest of the workflow in a script called quick_test_final.py.