Embedded DuckDB Starts Simple. Then It Needs a Process Boundary.
Embedding DuckDB inside an API process is simple until native execution shares the same failure domain. A federated query crash showed why DBConvert Streams is moving interactive DuckDB work behind a supervised query worker.
While testing DBConvert Streams this week, our stream-api process died with SIGSEGV in the middle of a federated query. The client saw only curl: (52) Empty reply from server.
The crash happened in the interactive query path, where embedded DuckDB execution shared the same process as our API. The query was a routine multi-source join.
That is a good place to talk about embedding native engines in production-facing processes. DuckDB is great embedded. It keeps deployment simple, avoids a separate analytical service, and gives the application powerful SQL over databases, files, and object storage.
But once that embedded engine sits inside the same process as your API, the failure domain changes.
The crash
The query was not exotic. It was a multi-source count and join:
SELECT
(SELECT COUNT(*) FROM my1.analytics.events) AS mysql_events,
(SELECT COUNT(*) FROM pg1.public.users) AS pg_users,
(SELECT COUNT(*)
FROM my1.analytics.events m
JOIN pg1.public.users p ON p.id = m.user_id
WHERE m.event_id <= 5000000) AS join_5m_count;
The execution path looked like this:
UI, or a direct API call with curl/script
-> stream-api (embedded DuckDB)
-> PostgreSQL / MySQL / S3 / files
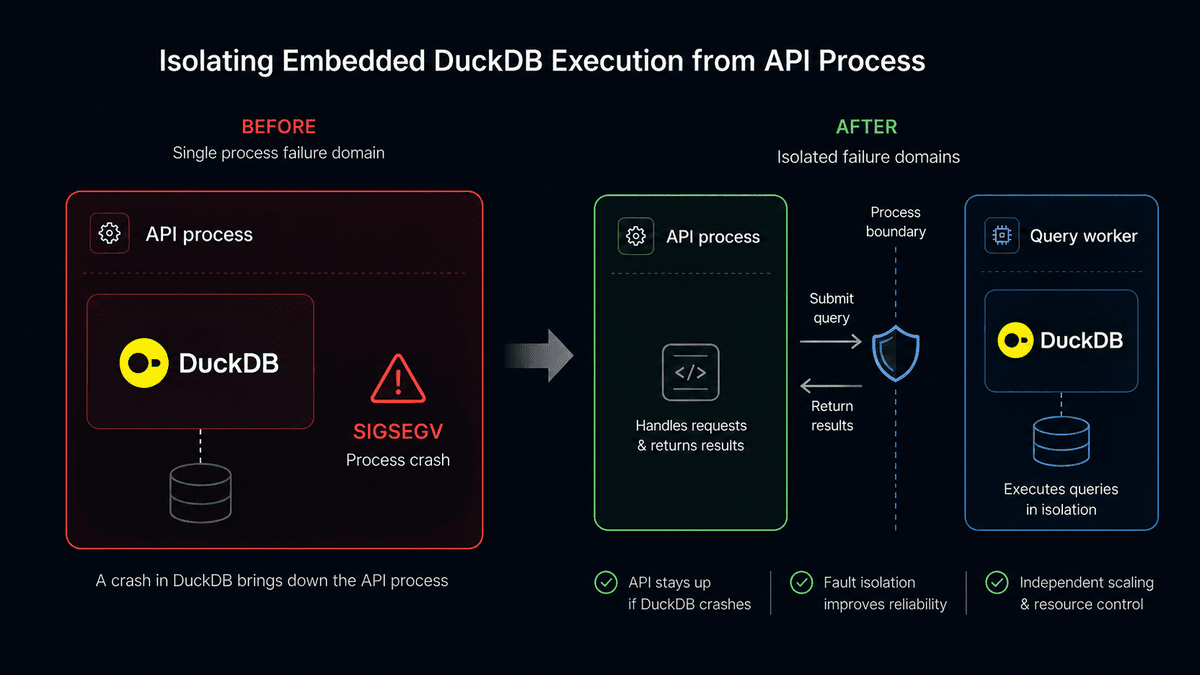
The diagram is the important part: interactive DuckDB execution and the API lived inside the same process. That made the API part of the blast radius.
Any Go service that embeds a CGO-based engine inherits the same risk. DuckDB and its scanner extensions run as native code inside the Go process. If that native layer dereferences bad memory or hits a segmentation fault, Go cannot turn it into a recoverable application error.
It is not a panic. It is process death.
The fix is a process boundary
Streams can move interactive DuckDB execution behind a supervised query worker:
UI or direct API call
-> stream-api
-> query worker (embedded DuckDB)
-> PostgreSQL / MySQL / S3 / files
If DuckDB or one of its scanner extensions crashes, the worker dies. The API stays alive. The UI receives a controlled failure instead of losing the server connection.
That separate worker also gives practical control over risky analytical queries:
- memory and CPU limits
- query cancellation
- worker restart after bad state
- separate telemetry for SQL execution
- better API responsiveness during heavy multi-source work
The point is not to add a new protocol. The point is to stop risky native execution from sharing a failure domain with the API.
What changes for DBConvert Streams
Today, the interactive federated query path is request-scoped. For each request, Streams attaches the requested sources, runs the query, then detaches sources and cleans up temporary state.
That was a safe first iteration. Source aliases, credentials, and temporary S3 secrets had to stay isolated across requests.
A supervised worker gives us a better place to manage that state.
A longer-lived workspace needs clear ownership and cleanup rules: who owns the state, when it expires, what happens when credentials change, and how much memory or disk it may use. With those rules in place, DuckDB can behave more like a multi-source SQL workspace instead of a one-request executor.
The same worker can also support repeated multi-source queries without rebuilding all source setup every time. For example, SQL Console could keep selected PostgreSQL, MySQL, S3, and file aliases available for a scoped session instead of attaching and cleaning them up for every preview.
Exports also get a cleaner responsibility split. stream-api should coordinate interactive work, not own query execution and result production. A query worker moves that responsibility outside the API process.
Multi-source SQL needs lifecycle control
Multi-source SQL is useful, but it is also a great way to find ugly execution paths.
A single query can touch live database scanners, network paths, S3 reads, memory pressure, spills, and result delivery at the same time.
The important questions are not only about SQL correctness:
- can the query be cancelled?
- can it be limited?
- can it fail without killing the API?
- can temp state be cleaned up afterward?
- can the result be delivered without turning the API into a bulk data pipe?
This is where the query worker matters. It gives the analytical execution path its own lifecycle.
Conclusion
Embedded DuckDB can start inside the application. That is one of the reasons it is useful.
But risky interactive execution eventually needs its own process boundary.
For DBConvert Streams, that boundary protects the API from native scanner crashes, memory spikes, bad joins, and long-running exploratory SQL.
The same lesson applies to any service that embeds native code inside its primary API process. If a scanner bug, extension crash, or unsafe native call can take down the API, you need the worker boundary.