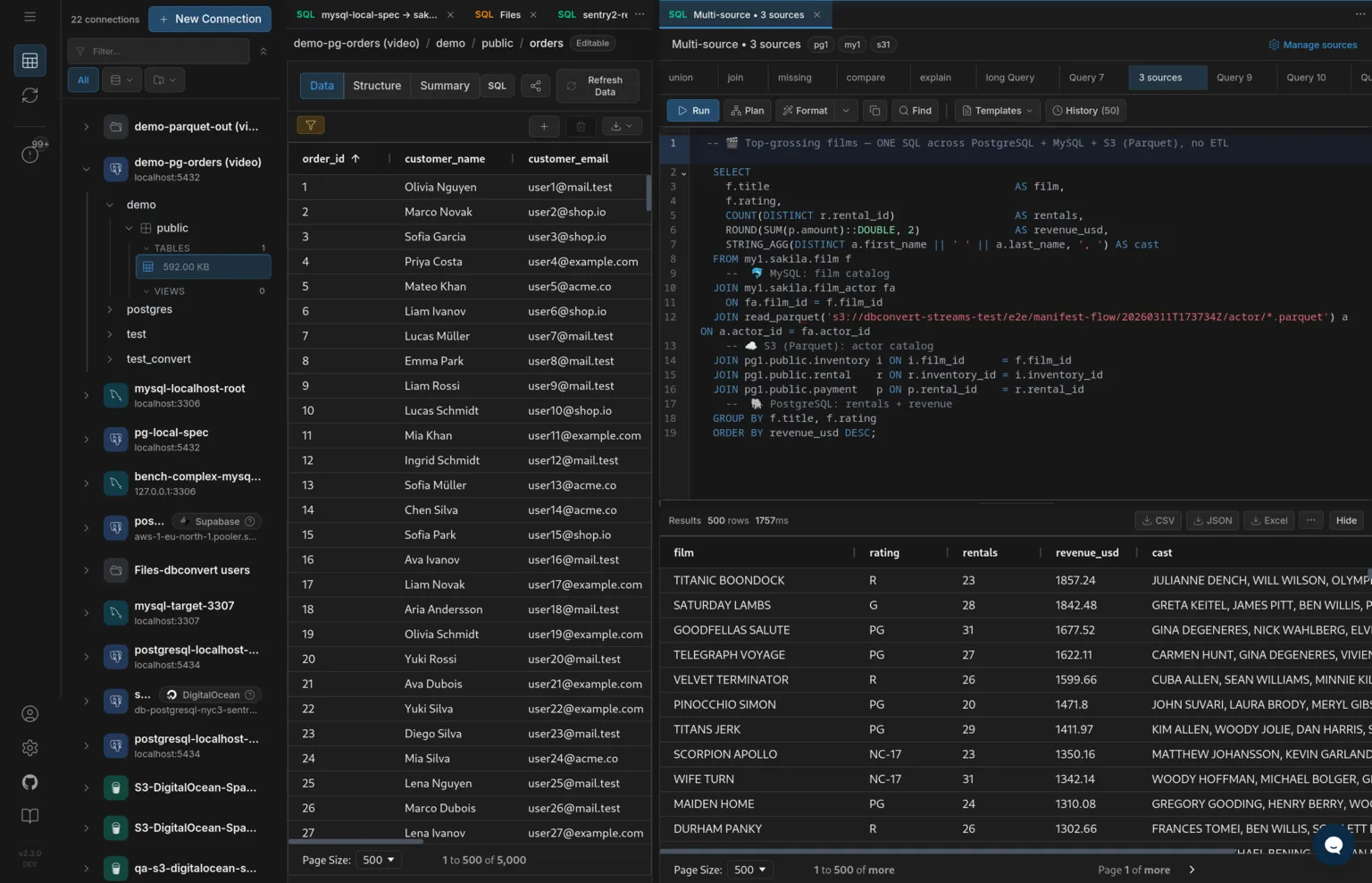
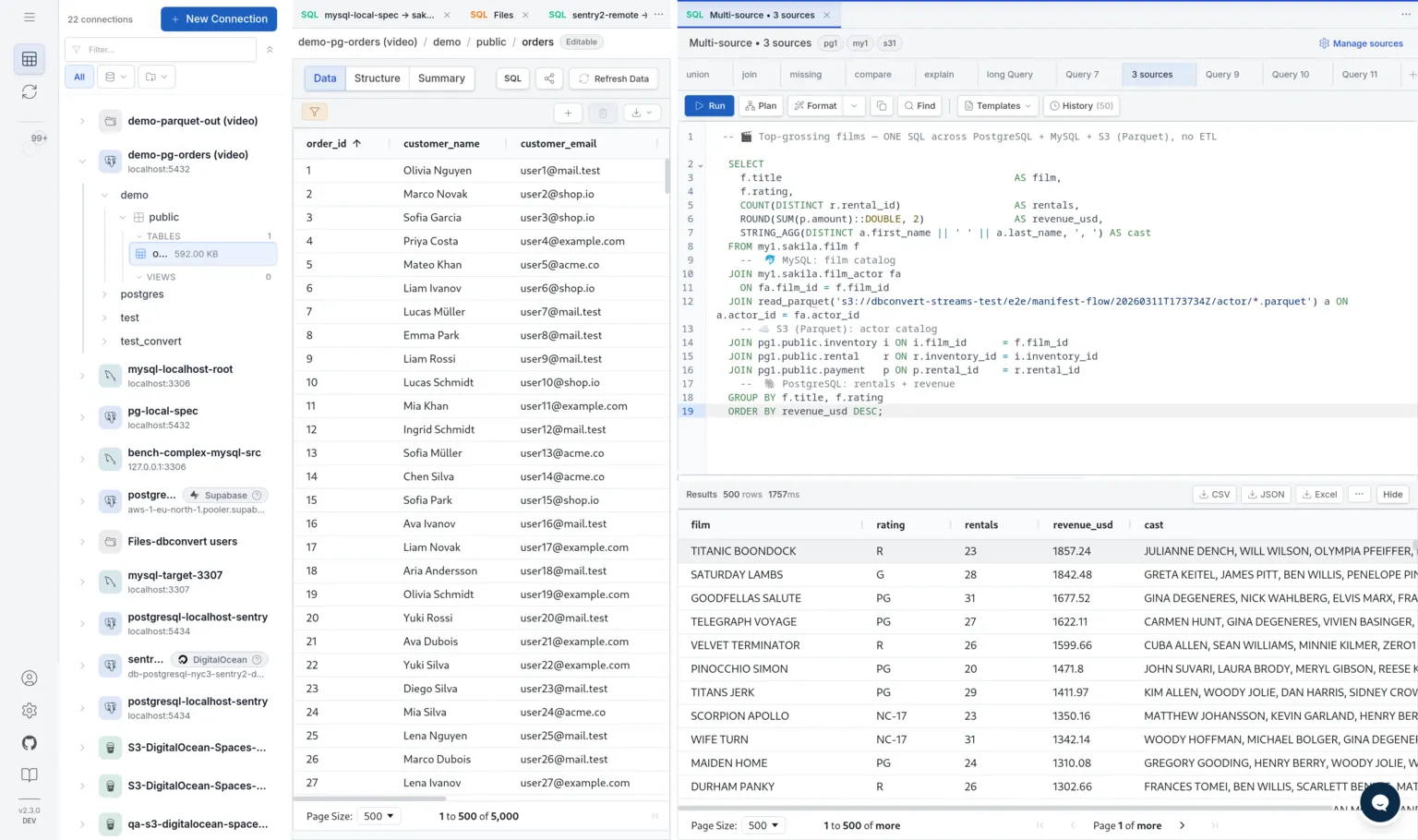
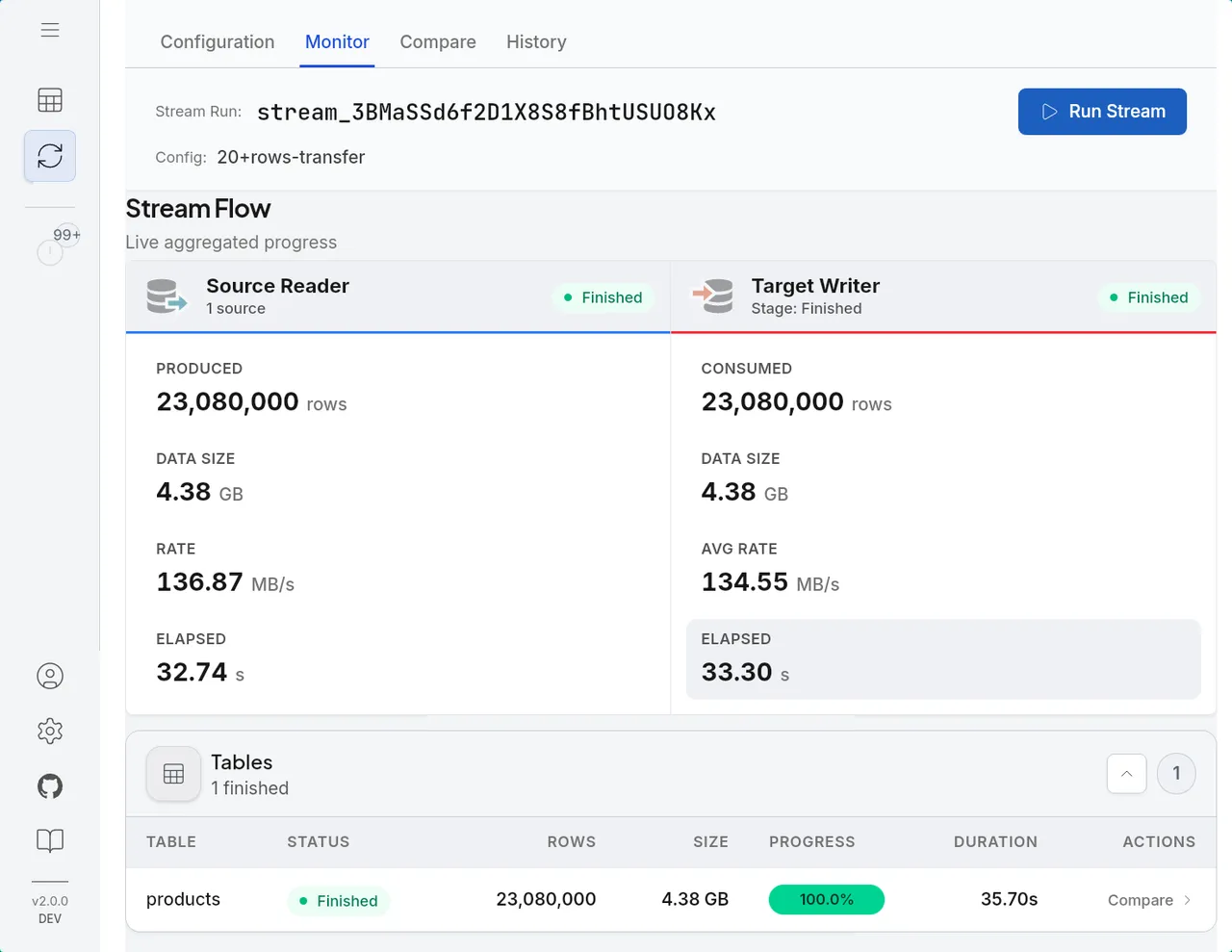


What is DBConvert Streams?
A self-hosted product that combines a free SQL IDE for PostgreSQL, MySQL, files, and S3 with a paid streaming engine for one-time migration and ongoing CDC replication. One install handles exploration, validation, migration, and replication.