Cross-Database Migration with Automatic Schema Conversion
- Schema converted
- Validated
- Resumable
- Parallel writes
Cross-database migration moves schema and data from one engine to another — for example, MySQL to PostgreSQL — without manual DDL, without lossy intermediate exports, and without staging tables. The hard part is rarely reading rows; it is converting types correctly, recreating indexes and foreign keys in a safe order, and recovering when a load stops mid-copy.
DBConvert Streams handles those parts in one stream: schema is converted automatically with visible type mappings, the load is split into primary-key ranges so it can resume from where it stopped, and a Compare view shows source against target before you flip production traffic.
Measured Performance
Load Throughput You Can Measure
Real numbers from local migration tests.
100 MB/s
per stream throughput
10M rows
migrated in ~15s (local)
50+ GB
verified, no upper limit
Per-stream
parallel write workers
MySQL → PostgreSQL local benchmark. Performance depends on hardware, row size, and database configuration.
Flexible Migration Scope
More than standard table-to-table migration.
- Full database
- Selected tables
- Filtered tables
- Custom SQL query
- Custom SQL with joins across databases and files
- Local files (CSV, JSON, JSONL, Parquet)
- S3 storage (with compression support)
Example
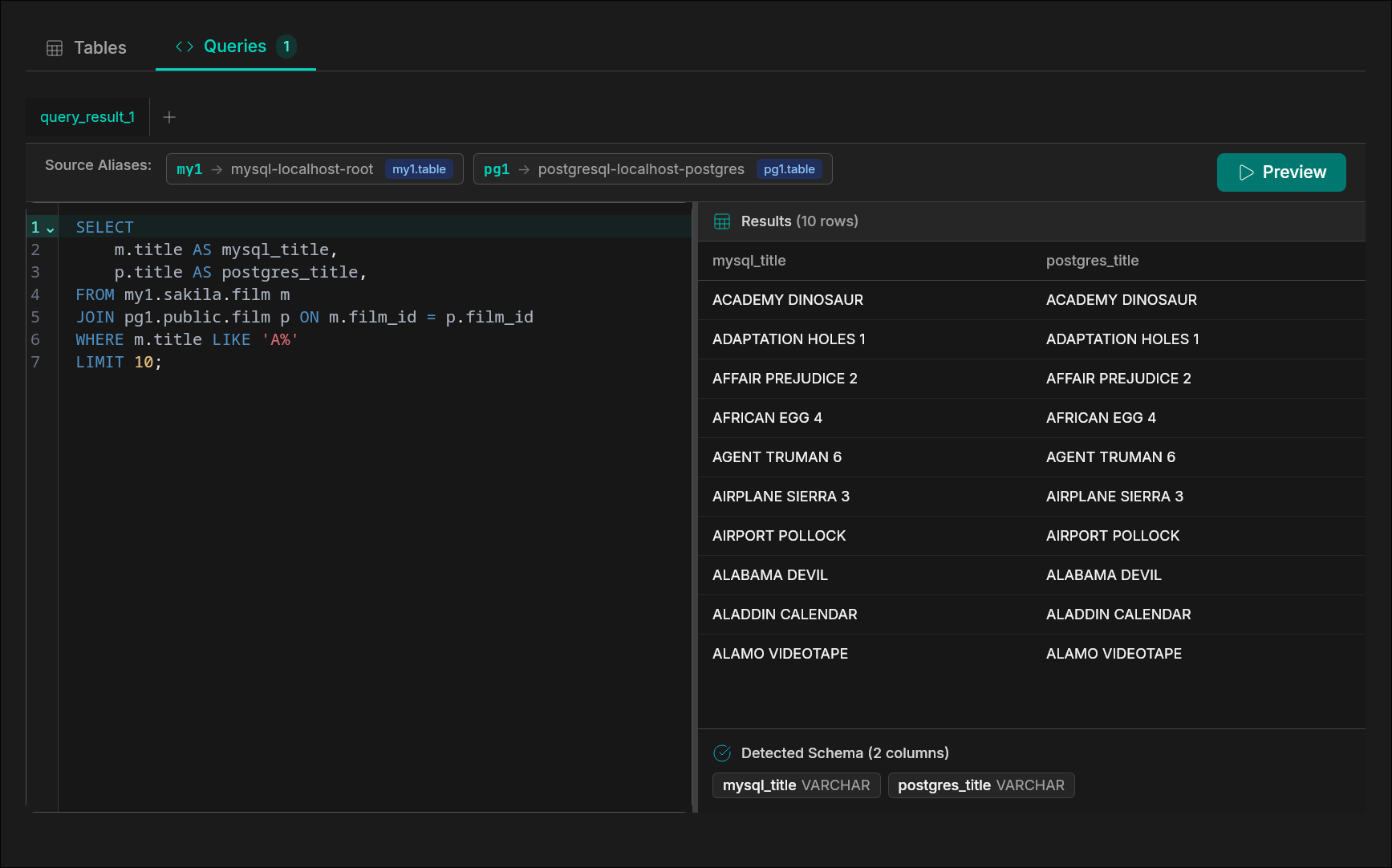
Join a CSV and a production MySQL table, then migrate the result into PostgreSQL — without staging tables. Powered by Cross-database SQL.
Cross-Database SQL in Action
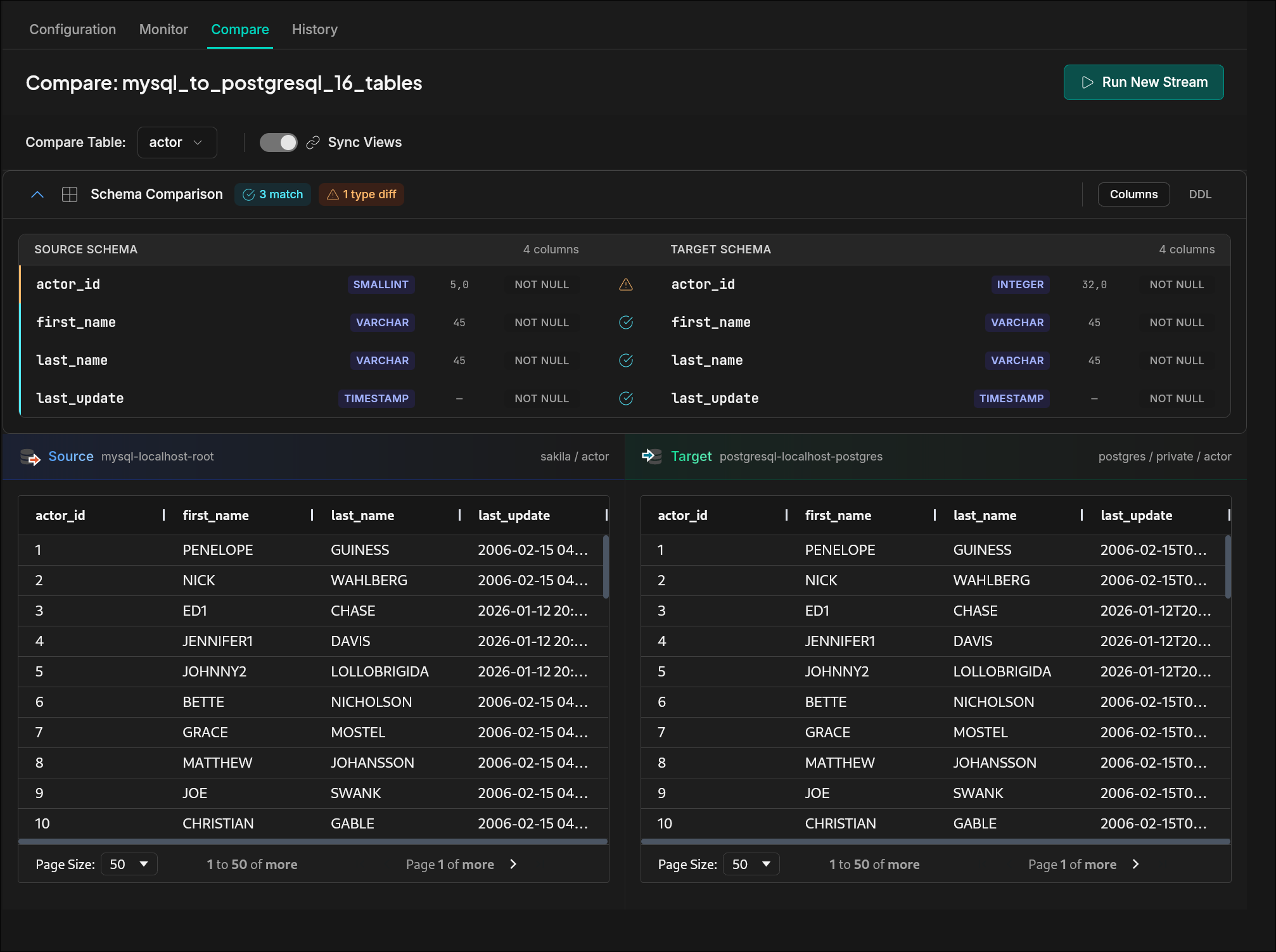
Automatic Schema Conversion & Built-In Validation
No manual DDL rewriting required.
Supported Migration Paths
- MySQL to PostgreSQL
- PostgreSQL to MySQL
- Database to files (CSV, JSON, Parquet)
- Files to database (schema inferred automatically)
- MySQL / PostgreSQL to Snowflake (Coming Soon)
Schema Conversion Handles
- Automatic MySQL ↔ PostgreSQL type mapping (INT → BIGINT, JSON → JSONB, ENUM → VARCHAR, etc.)
- Index and constraint recreation
- Foreign keys recreated in dependency-safe order
- Tables and column definitions
Database Migration Workflow
1. Define source and scope
Select the source, pick tables or write a SQL query, and apply row filters.
2. Configure schema and write behavior
Set schema policy (create, drop+create, skip) and write mode (insert, upsert, replace) independently for structure and data.
3. Run the migration
Data is read and written to the target in parallel through embedded JetStream.
4. Monitor progress
Track rows, data size, throughput, and per-table completion in real time.
Large loads continue from where they stopped
Eligible loads into MySQL or PostgreSQL targets are split into primary-key ranges. If the stream stops mid-copy, the next start resumes from the last completed chunk — not from the beginning.
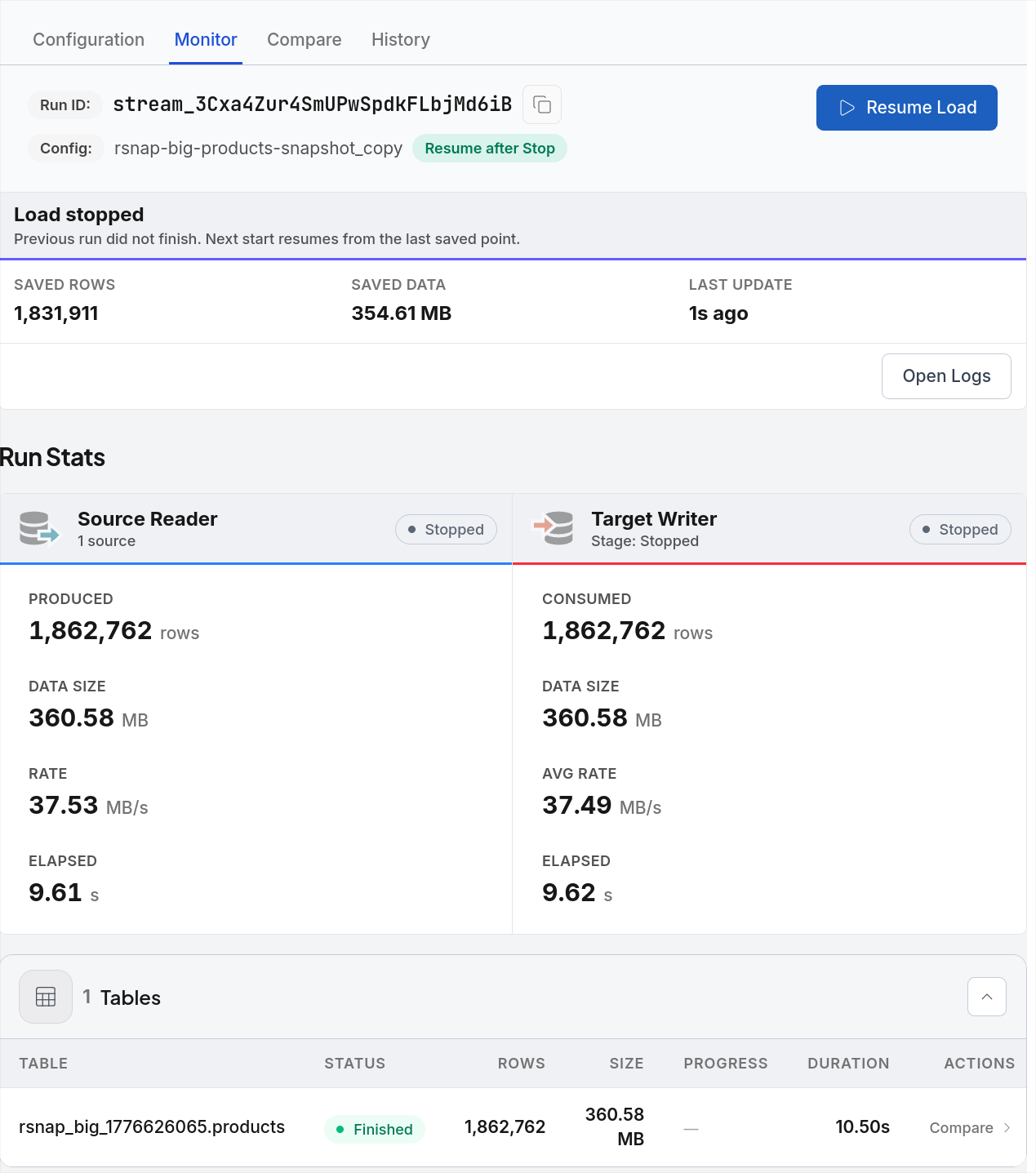
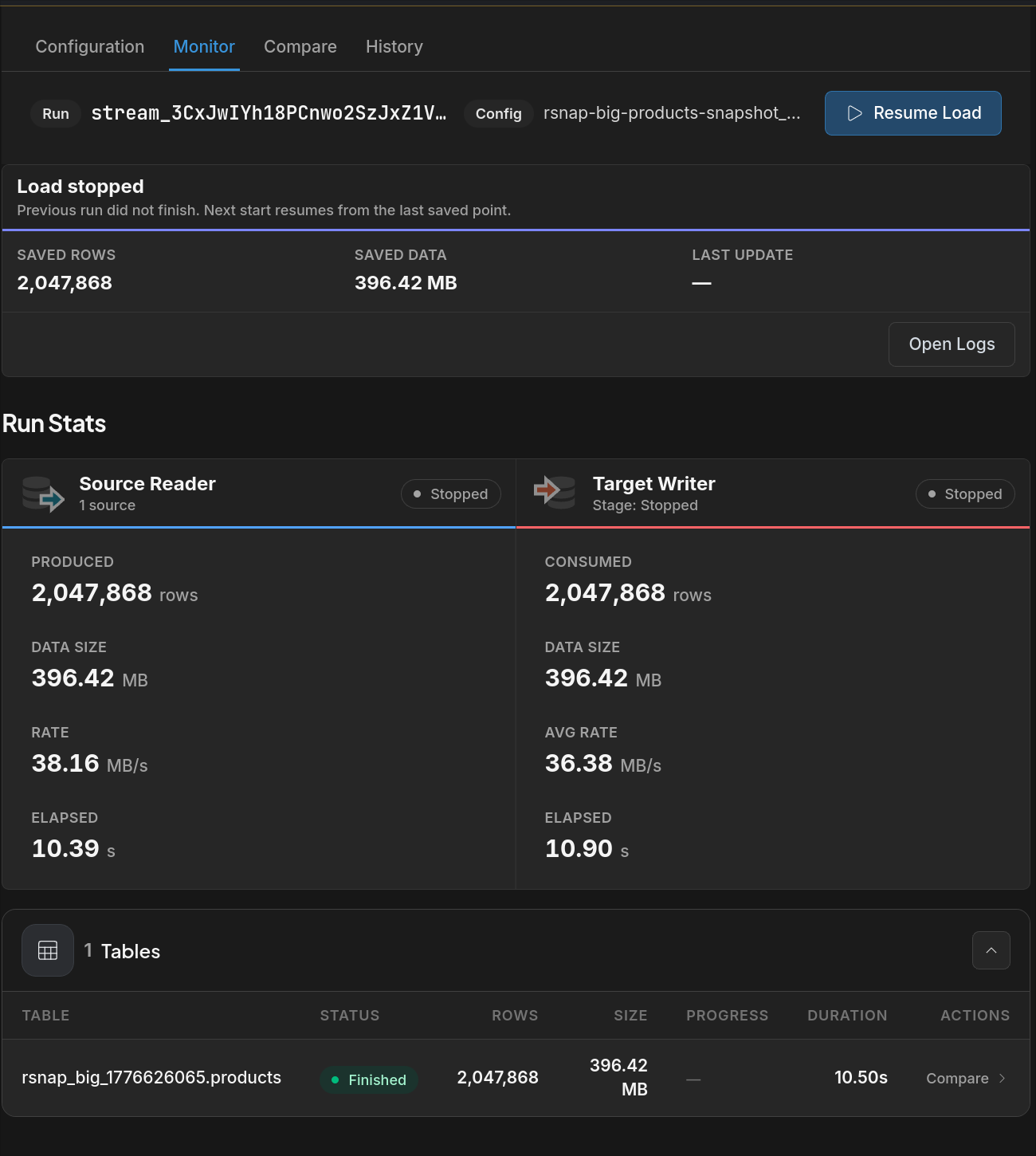
The monitor shows saved row count and data size from the interrupted run. Resume Load continues from the last saved point.
Common Use Cases
MySQL → PostgreSQL Modernization
Move a production MySQL database to PostgreSQL — schema conversion handled automatically.
On-Prem to Cloud Migration
Move self-hosted databases to cloud targets with a staged rollout and planned cutover.
Environment Seeding
Clone a production database subset into staging or dev for testing without affecting the primary.
Source Consolidation
Combine multiple databases and files into a single target database or storage destination.
Operational Exports
Export table or query results to CSV, JSONL, or Parquet in local storage or S3.
Related workflows
Before and after migration
Validate before cutover, build the source from multi-database SQL, or keep the target current after the load finishes.
Validate structure and data first
Inspect schemas, compare what landed, and review data before production migration windows.
Use SQL as the migration source
Build the source dataset from multiple databases, files, or S3-backed inputs before writing to the target.
Keep the target current after the load
Switch to CDC after the load finishes to keep the target current through cutover.
Run a migration test before the cutover window
Use compare output and run history to confirm the converted target before you schedule the production move.
Use pricing when you are ready to size production streams and seats.