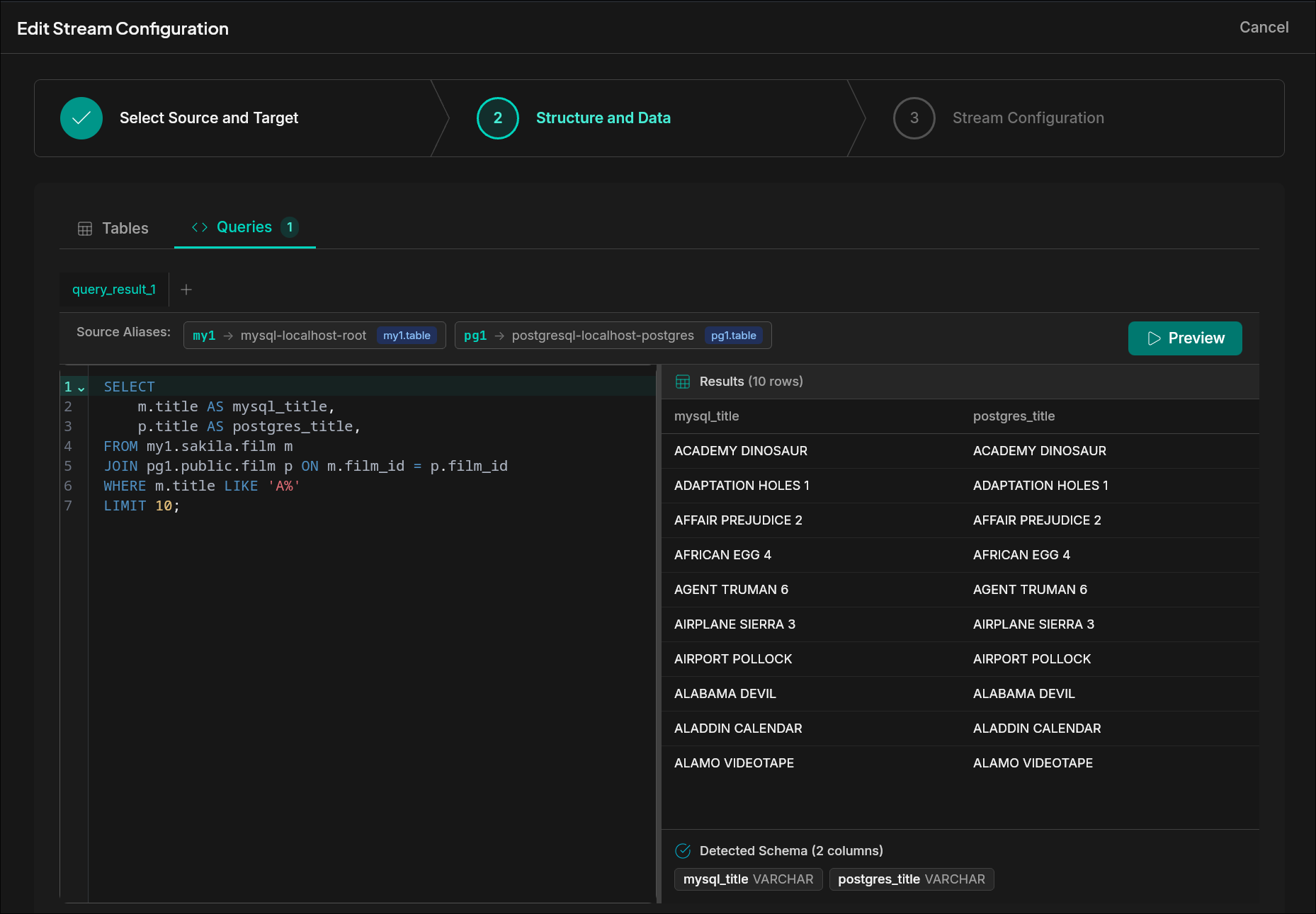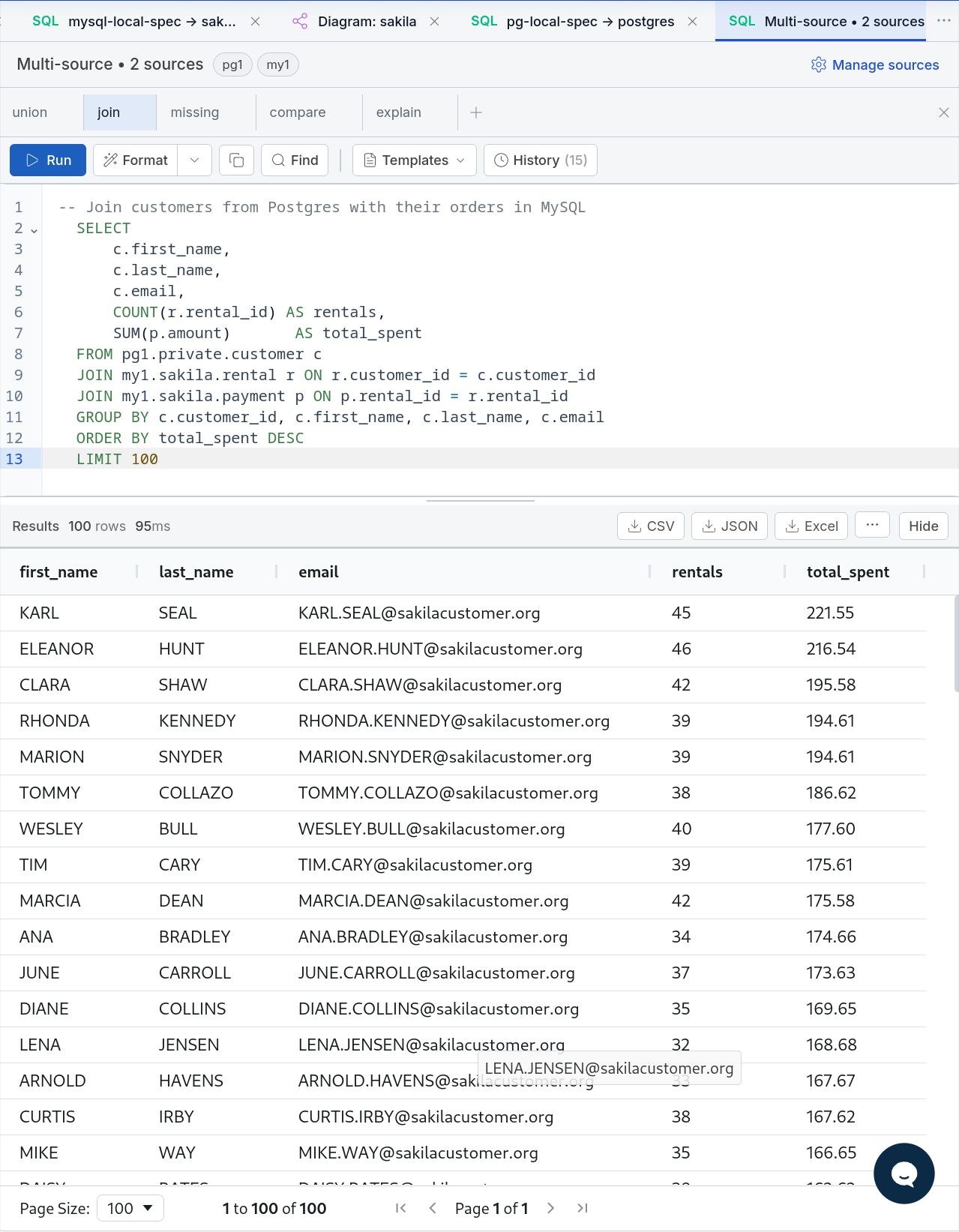
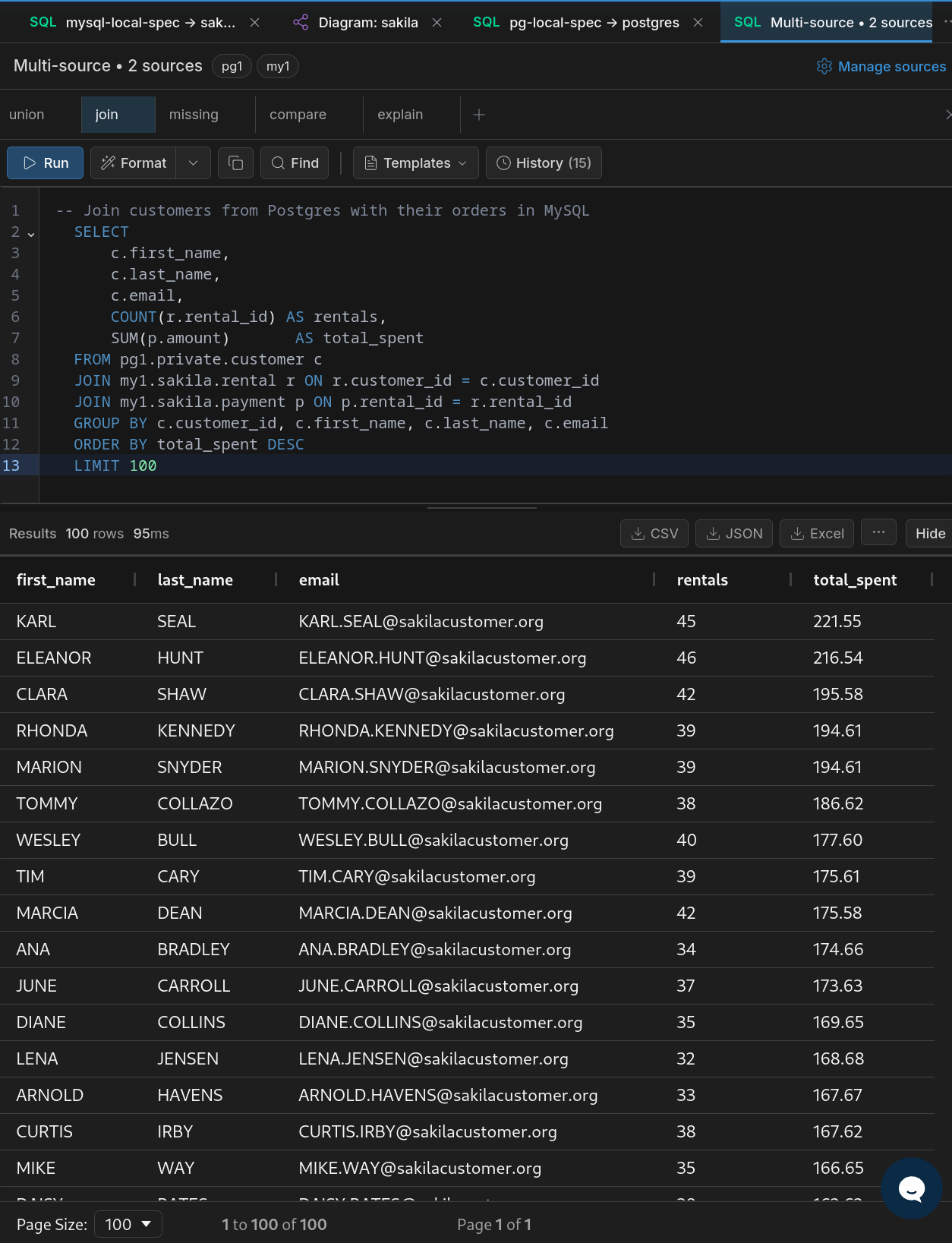
Cross-Database JOIN (PostgreSQL + MySQL)
SELECT
a.first_name || ' ' || a.last_name AS actor_name,
f.title AS film_title
FROM pg1.public.actor a
JOIN pg1.public.film_actor fa ON a.actor_id = fa.actor_id
JOIN my1.sakila.film f ON fa.film_id = f.film_id
LIMIT 20;Joins tables across PostgreSQL and MySQL in a single query — no export, no import, no staging.